
01-webpack概述及背景
背景
打包工具对比
webpack版本对比(webpack5)(程度视基础能力而定)
为什么有这些变化,解决了什么问题
基本配置
entry out loader plugin
文件指纹
打包工具对比
FIS3
一开始FIS3是百度开发出来给自己用的,官网定义:
解决前端工程中性能优化、资源加载(异步、同步、按需、预加载、依赖管理、合并、内嵌)、模块化开发、自动化工具、开发规范、代码部署等问题。
构建原理
FIS3是基于文件对象进行构建的,每个进入 FIS3 的文件都会实例化成一个 File 对象,整个构建过程都对这个对象进行操作完成构建任务
流程:
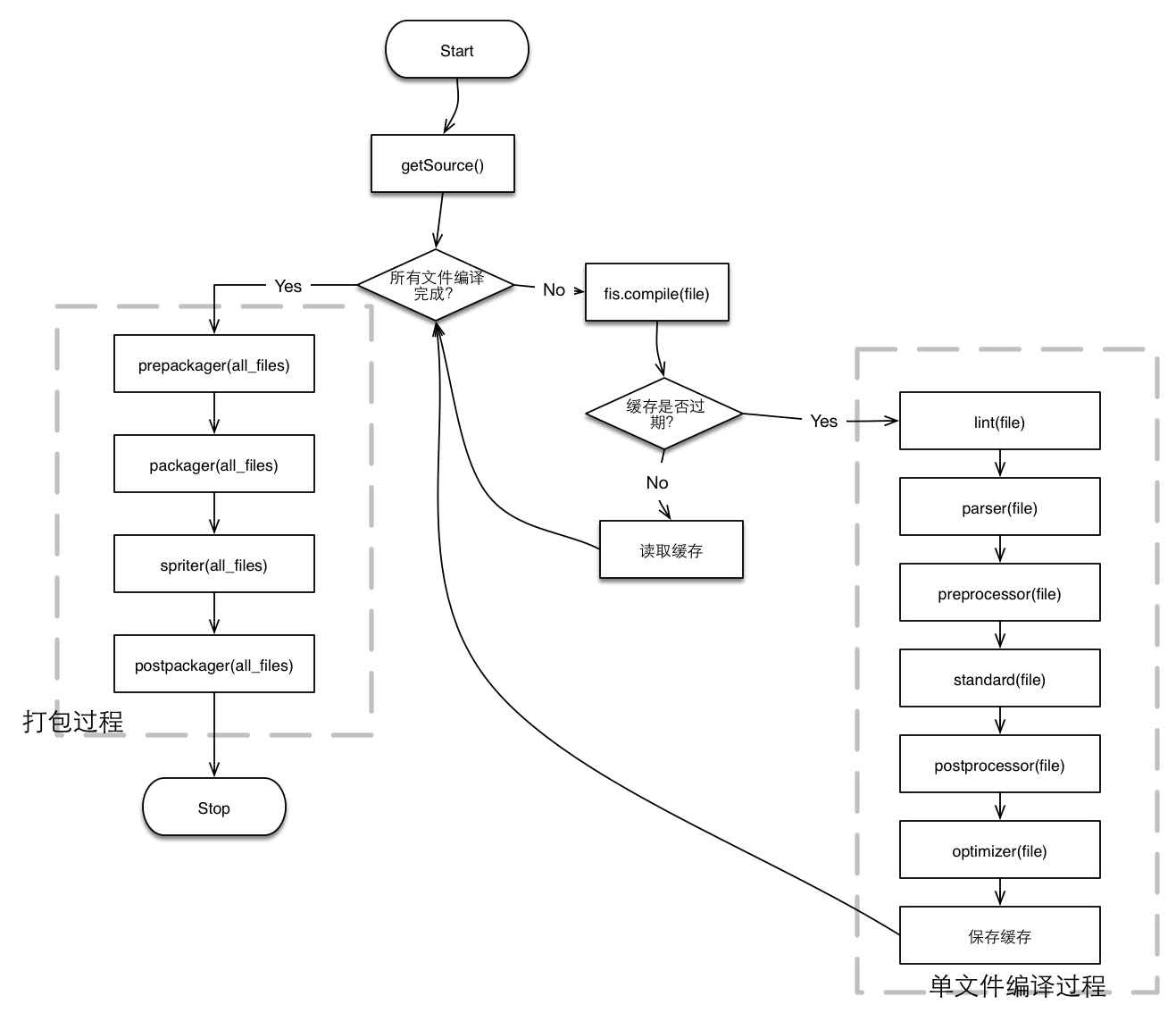
扫描项目目录拿到文件并初始化出一个文件对象列表
对文件对象中每一个文件进行单文件编译
获取用户设置的 package 插件,进行打包处理(包括合并图片)
单文件编译的过程
lint:代码校验检查,比较特殊,所以需要 release 命令命令行添加 -l 参数
parser:预处理阶段,比如 less、sass、es6、react 前端模板等都在此处预编译处理
preprocessor:标准化前处理插件
standard:标准化插件,处理内置语法
postprocessor:标准化后处理插件
文件打包的过程:
prepackager 打包前处理插件扩展点
packager 打包插件扩展点,通过此插件收集文件依赖信息、合并信息产出静态资源映射表
spriter 图片合并扩展点,如 csssprites
postpackager 打包后处理插件扩展点
构建过程会分析每一个文件的依赖关系,生成一个资源表sourceMap,资源表记录每一个文件的依赖关系,以及发布前的位置,和发布后的去向。
内容嵌入
FIS3 支持一种内置语法,可以通过?__inline标记将资源嵌入html、css、js中,
特点
优点:
FIS3非常灵活,因为只收集文件的各种依赖关系,不限制一个输入输出,可以根据sourceMap自定义输出规则。
适合多页面打包
fis不但能通过require,import等查找依赖,而且会搜寻src,href等各处与资源定位有关的地方,将他们计入依赖列表。
缺点
国产,维护不迅速
插件没有webpack多
gulp
gulp是基于nodeJS的两个重要模块:FileSystem 和Transform Stream 实现对文件和数据流的操作,并且借鉴了Unix的管道(pipe)的思想,使得处理过的对象从上一个流安全的流入下一个流。但是Gulp没有直接使用这两个模块,而是在FileSystem 和Transform Stream的上面包装了一层vinyl,使流的操作更加简单。
流式处理
src是输入
dest是输出
每个独立操作单元都是一个task,使用pipe来组装tasks
Rollup.js
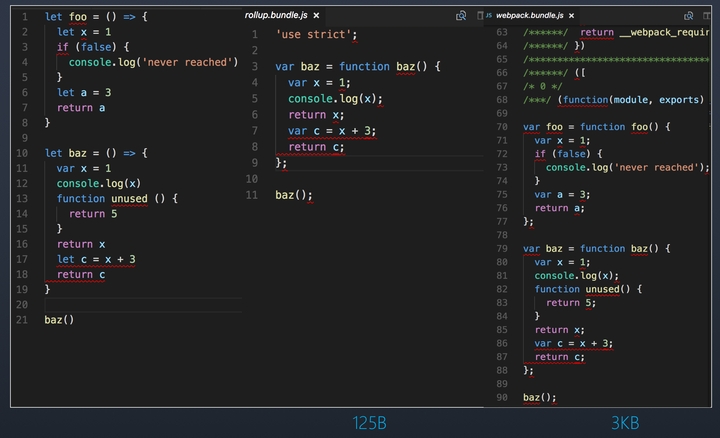
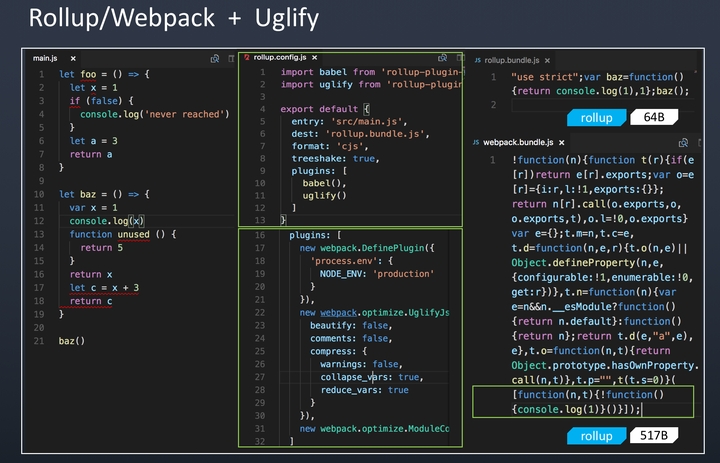
Tree-shaking
这个特点,是Rollup最初推出时的一大特点。Rollup通过对代码的静态分析,分析出冗余代码,在最终的打包文件中将这些冗余代码删除掉,进一步缩小代码体积。这是目前大部分构建工具所不具备的特点
ES6
Rollup基于ES6,可以是用ES6的import语法,不用管模块规范是 CommonJS 还是 AMD,ES6 模块可以使你自由、无缝地使用你最喜爱的 library 中那些最有用独立函数,而你的项目不必携带其他未使用的代码
不用使用babel等转成ES5(运行环境支持ES6,一般为基础库)
parcel
来自网上的一个比喻:在用了很久 Webpack 后用 Parcel 的感觉就像用了很久 Android 机后用 iPhone,不用再去操心细节和配置,大多数时候 Parcel 刚刚够用而且用的很舒服。
Parcel 是一个Web应用程序 打包器(bundler) ,与以往的开发人员使用的打包器有所不同。它利用多核处理提供极快的性能,并且你不需要进行任何配置。
Parcel 基于资源的。资源可以代表任何文件,但 Parcel 对 JavaScript ,CSS 和 HTML 文件等特定类型的资源有特殊的支持。Parcel 自动分析这些文件中引用的依赖关系,并将其包含到 输出包(output bundle) 中。相似类型的资源被组合在一起成为相同的输出包。如果您导入不同类型的资源(例如,如果你在 JS 中导入了一个 CSS 文件),它新建一个子包,并在父级中保留一个引用。这将在下面的部分中进行举例说明。
打包过程:
1、 构建资源树 Parcel 接受单个入口资源作为输入,可以是任何类型:JS文件,HTML,CSS,图像等。在Parcel 中定义了各种资源类型,它们知道如何处理特定的文件类型。 资源被解析,他们的依赖关系被提取,并被转换成最终的编译形式。 这个过程创建了一个资源树。
2、构建打包树
一旦资源树构建完成,资源就被放入打包文件树中。 为入口资源创建一个包,并且为动态的 import() 创建子包,这会导致代码拆分的发生。
当导入不同类型的资源时,兄弟文件包会被创建,例如,如果你从 JavaScript 导入 CSS 文件,它将被放入兄弟文件包到相应的 JavaScript 中。
如果一个资源需要被打包到多个文件中,它会被提升到文件束树中最近的公共祖先中,这样该资源就不会被多次打包。
3、打包
打包文件树被构建之后,每个包都由特定于该文件类型的 packager 写入文件。打包器知道如何将每个资源的代码合并到可以让浏览器加载的最终文件中。
特点
优点
零配置,只需要将它指向应用程序入口点,就能正常工作
构建快速,具有文件系统缓存,可以保存每个文件的编译结果
打包速度快
缺点:
html不支持热更新
不支持tree sharking
新的打包工具,插件和生态没有webpack的支持度好
webpack
起源于2012年,用于解决当时现有工具未解决的的一个难题:构建复杂的单页应用程序(SPA)
为什么选用webapck
打包工具
配置难度
特点
FIS3
成本高
输入输出灵活,大而全,但应用场景尴尬
gulp
中等
流式处理
rollup
中等
treeshaking、ES6、体积特比小
webpack
中等
SPA、 代码分割 、功能强大
parcel
低
速度快,但生态和功能不完善
webapck 发展历史
来扒一扒webpack是怎么诞生的,webpack是是一个德国人创建的,这个家伙不是搞前端的

sokra 一开始是 写 Java 的,Java 里面有个很出名的技术 叫 GWT(Google Web Toolkit),GWT 是把 Java 代码转换成 JavaScript ,也就是让后端来写前端,本质上也是在 AST 层面对代码做一成转换,Babel 也是干这件事的,但是 GWT 这门技术没有流行起来,后面 Google 也不推广了。
GWT 里面有个 feature 叫 「code splitting」,于是 他当时给用来做前端项目 Bundle 的 node.js 库 modules-webmake 提了一个 issue ,希望他们能实现, 「code splitting」就是 Webpack 现在提供的主要功能,也是当代前端的基石
modules-webmake 维护者一直没有实现这个功能,这个 issues 现在还 open 着,大家可以点进去看看,sokra 的回复很有意思的 于是 sokra 就 fork了一份 modules-webmake 代码 ,在github上开了一个新的项目 webpack,时间是 2012年3月10号,记住这个伟大的日子,Webpack这个伟大的项目就这样诞生了!!!!,估计 sokra 当时也没想日后 Webpack 会这么流行,成为前端开发的标配 所以 Webpack 最开始的 功能主要是 Bundle,特点是「code splitting」 看看, Webpack 也是 fork 其他项目,Babel 的核心 @babel/core 库 是fork 的 acorn 库,所以大家拉个 github 库到本地,改改自己用,不用不好意思 Webpack 诞生了,但它是怎么流行起来了,这个也很有意思,我们把时间回拨到2013年,这一年,React 开源了,React 是 Facebook 在 2012年内部使用的一个框架,同年 Facebook 收购了 Instagram,所以 Instagram 也是用的 React ,Instagram是一个图片的社交网站,图片还是高清的,对页面性能要求那是相当高的
原文可以参考这里
webpack火起来主要是因为SPA,让他们
webpack1
支持CMD和AMD,同时拥有丰富的plugin和loader,webpack逐渐得到广泛应用。
webpack2
支持ES Module,分析ES Module之间的依赖关系,
webpack1必须将ES Module转换成CommonJS模块,2支持tree sharking
webpack3
webpack3做的就是在2的基础上进行一些优化和改进
新的特性大都围绕ES Module提出,如Scope Hoisting和Magic Comment;
webpack3以上基本上都可以解决es6提出的模块化
webpack4
可以解决es6模块化【 export default / export import 】
更多个功能性 pulgin【 插件 】 和 loader 【 转换器 】
并行打包
webpack-cli从webpack中分离出来了
添加了mode模式,值可选有两个 development 和 production,对不同的环境他会提供不同的一些默认配置,
webpack3 迁移到 webpack4
目前在需求开发中,面临很多的一个问题:如何快速的从webpack3迁移到webpack4
基本条件的升级
node版本>6.0
升级webpack,webpack从4.0起,拆分成webpack和webpack-cli两个包,所以需要先卸载掉webpack,再重新安装webpack和webpack-cli
mode:webpack配置文件必须增加mode选项
第三方的插件和loader
第三方的插件和loader是webpack的强大功能的保证,要对每一个插件和loader进行确认是否需要升级,因为对于webpack不同版本的3和4,某些插件和loader可能会出错,这是升级webpack中工作量比较大地方,需要对照插件和loader的官网看书否需要升级。
webpack 5 新特性
持久化缓存
多进程
html css提升为一等公民
按需加载支持文件名模式(块ID)
使用long-term caching解决生产环境下moduleIds & chunkIds变化的问题
优化minSize&maxSize的配置方式
Node.js polyfills 自动加载功能被移除
HMR功能优化,代码单独抽离出来
打包体积
webapck4打包

webapck5打包

webpack基本配置
webpack 5大基本配置
entry
output
loader
plugin
mode
webpack.config.js
详细配置见webpack官网,这里简单列举一下:
entry 和 output
入口:指示 webpack 应该使用哪个模块,来作为构建其内部依赖图的开始
出口:控制 webpack 如何向硬盘写入编译文件
loader
因为webpack 自身只理解 JavaScript。 loader 可以将所有类型的文件转换为 webpack 能够处理的有效模块,然后你就可以利用 webpack 的打包能力,对它们进行处理。
在 webpack 的配置中 loader 有两个目标: 1. test 属性,用于找到 出需要被 loader 进行转换 的某个或某些文件。 2. use 属性,表示进行转换时,应该使用哪个 loader

图中的配置 告诉 webpack 编译器(compiler) 如下信息: “嘿,webpack 编译器,当你碰到「在 require()/import 语句中被解析为 '.js' 的路径」时,在你对它打包之前,先使用 babel-loader 转换一下。
三种使用loader的方法:
基本配置(推荐)
loader 支持链式传递。能够对资源使用流水线(pipeline)。一组链式的 loader 将按照相反的顺序执行。loader 链中的第一个 loader 返回值给下一个 loader。在最后一个 loader,返回 webpack 所预期的 JavaScript。
内联
CLI
plugins
loader 被用于转换某些类型的模块,而插件则可以用于执行范围更广的任务。插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量。插件接口功能极其强大,可以用来处理各种各样的任务。
插件目的在于解决 loader 无法实现的其他事
参考
Last updated