> For the complete documentation index, see [llms.txt](https://xia-ao.gitbook.io/notes/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://xia-ao.gitbook.io/notes/computer/browser/webkit-jie-xi-css.md).
# webkit解析CSS过程详解
## 浏览器解析六部曲
浏览器解析页面主要分为六个步骤,如下:

我们先看前三个步骤,解析DOM树和CSSOM树,然后何合成render树。

之后再进行布局,绘制,合成。在这个过程中,我们来看看我们平常写的css样式代码是怎么解析的。
### CSSStyleSheets
分析之前,我们先看一个对象,CSSStyleSheets,方便我们后面理解。
* CSSStyleSheets是CSSOM定义的样式表接口,可以在js中访问,通过该接口,开发者可以通过js获取样式表的各种信息。例如`type` `cssRules` 规则信息等。
* 可以通过`document.styleSheets`访问到CSSStyleSheets。
* `styleSheets`是CSSOM对DOM中`document`接口进行了扩展,让我们可以访问。
* 页面`document.styleSheets`对象是一个`StyleSheetList`类数组对象,里面包含页面所有样式
以下示例代码:
```markup
this is a big error
this is also a
very big error error
```
抓取时使用的是performance 默认的3秒钟。
使用top left定位时3s渲染时间69.2ms
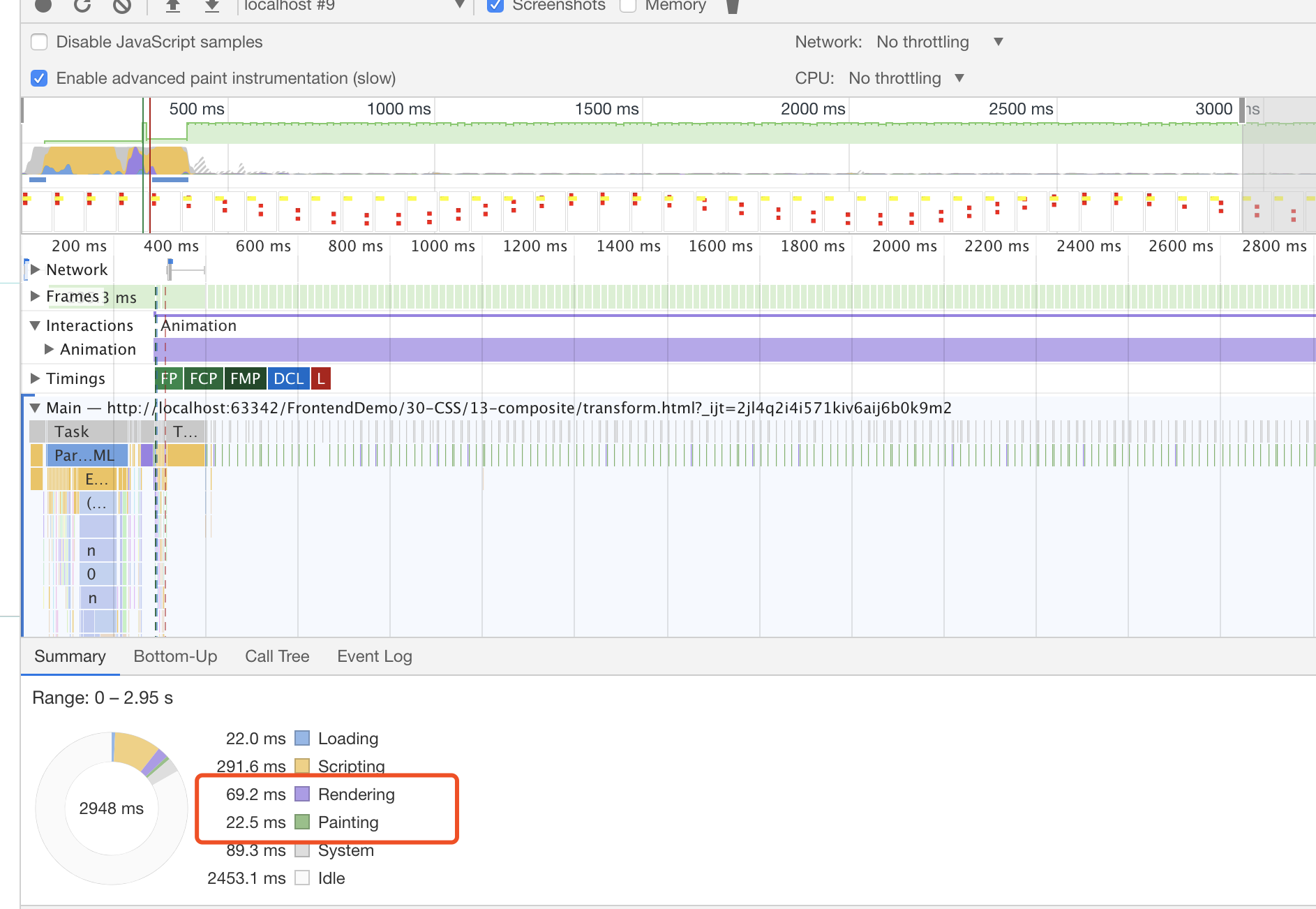
中间一直在render和paint

使用transform时 3s内渲染时间27ms,除了刚开始的渲染时间,后面没有再render和paint

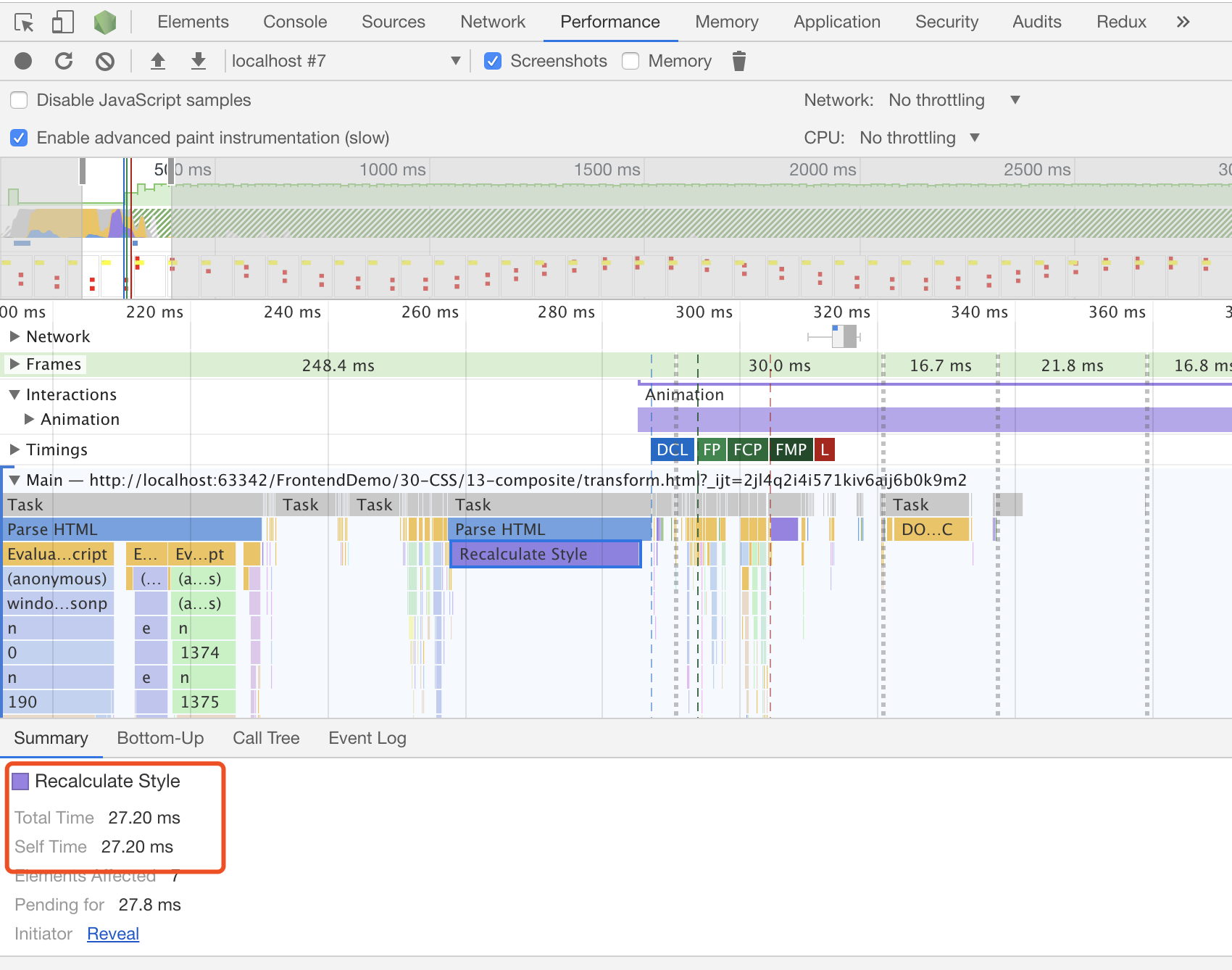
#### 题外话
贝贝首页图层layer


从这里可以看到,图层还是比较多的,有些地方因为`z-index`的原因,层级非常高,比如下方导航栏,明显可以看到层级高很多。
参考来源:
* 《webkit技术内幕》-朱永盛
* [浏览器的工作原理:新式网络浏览器幕后揭秘](https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/) - By Tali Garsiel and Paul Irish
* [CSS规范](https://www.w3.org/TR/CSS2/)
* [从Chrome源码看浏览器如何计算CSS](https://zhuanlan.zhihu.com/p/25380611) -
李银城
* [从Chrome源码看浏览器如何layout布局](https://zhuanlan.zhihu.com/p/25445527)
* [CSS属性影响](https://csstriggers.com/)
* [无线性能优化:Composite](http://taobaofed.org/blog/2016/04/25/performance-composite/)
* [chrome开发者文档](https://developers.google.com/web/fundamentals/performance/rendering/)
* [AssumedOverlap 原因分析](https://github.com/yoution/AssumedOverlap)
* [01 浏览器渲染优化](https://duola8789.github.io/2019/06/17/03%20%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/04%20%E4%BC%98%E8%BE%BE%E5%AD%A6%E5%9F%8E/01%20%E6%B5%8F%E8%A7%88%E5%99%A8%E6%B8%B2%E6%9F%93%E4%BC%98%E5%8C%96/)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://xia-ao.gitbook.io/notes/computer/browser/webkit-jie-xi-css.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.